Apache Sparkを活用したデータ分析基盤「Impulse」が進化、機械学習によるリアルタイム予測分析プラットフォームとしてリリースしました
2015年7月31日
当社は、データ分析基盤として提供している「Impulse」を機能強化し、リアルタイム予測分析プラットフォームとしてリリースしましたので、お知らせします。
最新版のImpulseでは、機械学習エンジンによる予測・異常検知のリアルタイム処理、大規模データのバッチ処理、インタラクティブな分析を行うOLAPといった機能を統一したプラットフォームで提供することにより、IoTデバイスから出力される大量のセンサーデータを用いた故障予測や、ITシステムやNW機器のリソースデータを用いた障害予兆検知などを実現します。
また、先端オープンソースの分散処理フレームワーク「Apache Spark」に加え、新たにアマゾン ウェブ サービス(以下、AWS)環境への導入に対応しました。ストリーミング処理からデータ蓄積、さらに大規模データの分散処理といった一連の処理を、Amazon KinesisやAmazon DynamoDB、Amazon Simple Storage Service(以下、Amazon S3)、Amazon Elastic MapReduce(Amazon EMR)等といったスケーラビリティを備えた各種AWSサービスを活用することにより、迅速かつ安価に大規模データ分析環境の提供を実現します。
◆背景と概要
企業活動において発生するデータは増大し続ける中、企業の競争力を強化するためにデータ分析の重要性が高まっています。様々な分析ツールが提供されている一方で、複雑化するビジネス課題を解決するためには、大規模化・多様化するデータに対して、高速かつ高度な分析が求められています。
そこで、当社は、Apache Sparkを活用した大規模データ分析基盤「Impulse」において、機械学習によるリアルタイム予測・分析機能を強化した最新版をリリースします。
Impulseの基盤は、ログ収集や、高速なデータ分析の分散処理フレームワーク、全文検索エンジンといった各種オープンソース(fluentd、Apache Spark、elasticsearch等)と、それらを企業用途で利用するための当社独自の拡張モジュールやプラグインによって、各種コンポーネントの連携と最適化を実現しています。最新版では、これまで提供してきた大規模データのバッチ分析機能に加え、機械学習エンジンによる予測・異常検知のリアルタイム処理やアドホックな分析に対応するためのOLAP等の分析機能を強化することにより、様々なビジネスシーンに活用可能な「リアルタイム予測分析プラットフォーム」を提供します。
さらに、オンプレミス環境への導入に加え、AWS環境への導入にも対応しました。Amazon Kinesisを利用したデータストリーミング処理、Amazon DynamoDBやAmazon S3といったストレージへのデータ蓄積、Amazon EMRによる大規模データ分散処理など、データ分析基盤に求められるスケーラビリティと高速処理をAWSの各種サービスを利用して実現しています。
AWS環境に対応することで、AWSの各種サービスのログデータ(Amazon CloudWatch、AWS CloudTrail、その他各種サービスのログ:Amazon S3、Amazon EMR等)を分析対象として扱うことが容易となり、システムリソースの最適化やセキュリティ、パフォーマンス改善を目的としたデータ分析が実現できます。
◆サービスの利用シーン
- IoTデバイスからのセンサーデータを用いた各種設備や製品の故障予測
- ITシステムのログデータ、リソースメトリクスを用いたシステム障害予兆検知
- ITサービスにおけるアクセスログ等を用いたパフォーマンス低下の異常検知
- ユーザーPCの端末操作ログや社内共通基盤へのアクセスログを用いた情報漏洩不正操作検知
- センサーやカメラデバイスからの画像データを用いた行動分析、など
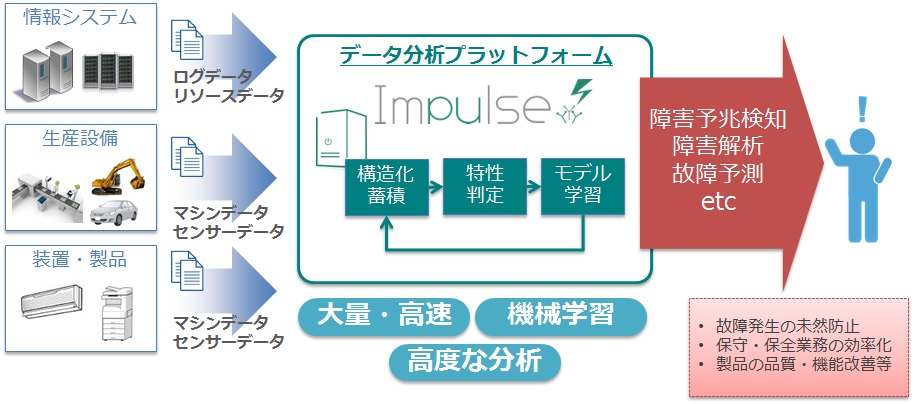
◆Impulseの機能と特徴
- 多様なデータのリアルタイム収集・蓄積
- 各種ログデータ、リソースメトリクス、センサーデータ等、様々なデータ収集・構造化に対応
- リアルタイムに収集したストリーミングデータをAmazon S3にアーカイブとして蓄積
- 機械学習によるリアルタイムなデータ分析
- リアルタイムに収集したデータに対して、機械学習アルゴリズムを利用した深い分析
* 変化点検出、相関分析、時系列解析
* クラスタリング
* テキストマイニング(テキスト要約・文言抽出)
* 回帰分析(需要予測) - リアルタイム分析とアドホック分析
* データ分析に必要な様々な統計・集計関数が利用可能
* データ分析のSQLクエリを用いて、リアルタイムでも、アドホックな分析でも実行可能
◆Impulseを活用したデータ分析サービス
当社では今後、リアルタイム予測分析プラットフォーム「Impulse」を活用して、ビジネス価値の創造またはビジネス損失の低減に寄与する様々なサービスを開発、提供していきます。
今後重要性を増してくるITシステムの統合的なログデータ管理サービス、システム障害予兆検知サービス、セキュリティの異常検知サービスや、普及を加速させるIoTデバイスのセンサーデータを用いた故障予兆検知サービスなど、順次提供サービスを拡大していきます。
【本件に関するお問合わせ先】
- ブレインズテクノロジー株式会社 担当:藤原
- TEL : 03-6455-7023
- E-mail : sales@brains-tech.co.jp
※アマゾン ウェブ サービス、Amazon Web Services、AWS、Amazon DynamoDB、Amazon EMR、Amazon Kinesis、Amazon CloudWatch、AWS CloudTrail、Amazon S3およびAmazon Web Services ロゴは、Amazon.com, Inc.またはその関連会社の商標です。
※Apache Sparkは、Apache Software Foundationの登録商標です。
※その他、記載されている会社名、製品名は、各社の登録商標または商標です。
【参考リンク】